
Phase 1
#1 Mathematische Modelle in der Magnetpartikelbildgebung
Cécile Pot d'or & Lasse Fischer, Universität Bremen
Kooperation: Universität Bremen, Universitätsklinikum Hamburg-Eppendorf
Dieses Innovation Lab beschäftigt sich mit der Weiterentwicklung eines Modells zur Systemmatrixsimulation in der Magnetpartikelbildgebung (MPI), das in [Albers et al., 2021] formuliert wurde. Beim MPI handelt es sich um ein biomedizinisches Verfahren, bei dem die nichtlineare Magnetisierungsreaktion von magnetischen Nanopartikeln (MNP) auf Magnetfelder beobachtet wird. Aus den gemessenen Spannungssignalen lässt sich die räumliche Verteilung der MNP-Konzentration bestimmen. Dies hat große Relevanz im Hinblick auf medizinische Anwendungen, in denen eine gute Lokalisierung der Partikel erforderlich ist.
Die Bestimmung der Systemmatrix ist ein wesentlicher Schritt, um das Problem der Bildrekonstruktion beim MPI zu lösen. Zurzeit ist noch ein zeitaufwendiges und speicherintensives Kalibrierungsverfahren nötig, um die Systemmatrix zu ermitteln. Durch eine modellbasierte Bestimmung der Parameter kann dieser Schritt umgangen werden. In unserem Ansatz wurde das in [Albers et al., 2021] vorgestellte Modell gegebene Modell erweitert, indem ein weiterer Optimierungsparameter betrachtet und gleichzeitig an das Modell angepasst wurde. Damit entsteht ein regularisiertes nichtlineares Optimierungsproblem, das wir numerisch gelöst haben. Unsere Ergebnisse zeigen, dass das Vorgängermodell einen geringeren Fehler verursacht, jedoch gibt es Grund zur Annahme, dass unsere Lösung näher an der Realität liegt.
Literatur
Albers, H., Knopp, T., Möddel, M., Boberg, M., and Kluth, T. (2021). Modeling the magnetization dynamics for large ensembles of immobilized magnetic nanoparticles in multi-dimensional magnetic particle imaging. Journal of Magnetism and Magnetic Materials.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 19.01.2022 erfolgreich abgeschlossen.
#2 Machine Learning/Deep Learning Methoden für Risserkennung
Shai Dimant & Justus Will, TU Kaiserslautern
Kooperation: Technische Universität Kaiserslautern, Fraunhofer ITWM Kaiserslautern
Das Ziel unseres Projektes war es, mithilfe von Methoden des maschinellen Lernens automatisiert Risse in großen Betonproben zu erkennen. Dazu haben wir ein 3D Convolutional Neural Network auf semi-synthetischen Daten trainiert. Zur Erzeugung dieser Daten haben wir Ausschnitte aus Bildern von Betonproben verwendet, die keinen Riss aufweisen und gegebenenfalls synthetisch erzeugte Risse hinzugefügt, welche mit Hilfe eines Brownian Surface simuliert wurden. Wir haben dabei Risse unterschiedlicher Breite und manchmal auch mehrere Risse pro Bild erzeugt. Unsere Evaluierung haben wir auf echten Aufnahmen von Beton vorgenommen. Wichtig waren uns hierbei vor allem ein hoher Recall (dem Anteil an erkannten Rissen), aber auch eine hohe True Negative Rate (dem Anteil an erkannten Bildern ohne Risse) und schnelle Laufzeit. So können wir eine effiziente und korrekte Erkennung gewährleisten und spätere Aufgaben wie die Segmentierung beschleunigen.
Für die Wahl der Netzwerkarchitektur und aller ihrer Hyperparameter haben wir uns die Performance auf einem Validierungsdatensatz realer Daten angeschaut.
Dabei ist es besonders wichtig, Overfitting zu vermeiden, also eine gute Generalisierung zu erreichen. Unsere Experimente zeigen, dass eine Convolutional Layer ausreichend ist, um Risse zu erkennen. Mehr Layer verbessern die Performance nicht, sorgen aber für längere Laufzeiten und schlechtere Generalisierung.
Um den Recall höher zu priorisieren, haben wir den Loss so angepasst, dass nicht erkannte Risse stärker bestraft werden. Eine weitere Möglichkeit weniger Risse zu verpassen besteht darin, den cut-off Wert anzupassen, um schon bei niedriger Sicherheit von einem Riss auszugehen. Da unser Netz aber alle synthetischen Trainingsdaten korrekt klassifizieren kann, lernt es sich sehr sicher zu sein, so dass fast alle vorhergesagten Wahrscheinlichkeiten nahe bei 0 oder 1 liegen, ohne die erhöhte Unsicherheit auf den realen Daten widerzuspiegeln. In Folge dessen, ändert eine Verschiebung des cut-off Werts wenig an der Klassifizierung.
Um eine bessere Generalisierung zu erreichen, haben wir Regularisierung verwendet. Eine klassische Regularisierungstechnik ist Weight Decay. Dabei wird zum Loss, der während des Trainings zu minimieren ist, als Strafterm die L2-Norm der Parameter hinzuaddiert. Dies sorgt dafür, dass kleine Gewichte bevorzugt werden und nur dann ein Feature erlernt wird, wenn es auch wirklich wichtig für die Klassifizierung ist. Darüber hinaus haben wir durch Drehungen und Spiegelungen all unsere Daten augmentiert. So erhalten wir pro Bild bis zu 48 augmentierte Bilder und können unsere Datensätze vergrößern, was wiederum zu einer besseren Generalisierung führt. Für unsere synthetischen Daten erzeugten wir zudem für jedes Bild neue Risse, sodass während des Trainings kein Riss doppelt gesehen wurde.
Eine weitere Möglichkeit der Regularisierung ist es Dropout in den linearen Layern zu verwenden. Dabei wird während des Trainings in jedem Durchlauf des Netzes ein Prozentsatz der Features nicht verwendet, indem einige Verbindungen der linearen Layer nicht berücksichtigt werden. In unseren Experimenten zeigten sich dadurch jedoch keine Verbesserung und wir verzichteten daher auf Dropout. Da die Aufnahmen typischerweise zu groß sind um als ganzes in den Arbeitsspeicher (bzw. Grafikspeicher) zu passen, haben wir die realen Daten in überlappende 100x100x100 Blöcke zerschnitten und diese dann mit unserem Netzwerk klassifiziert. Unser bestes Netz erzielte dabei auf einem kleinen von uns klassifizierten Testdatensatz realer Daten einen Recall von 93.10 %, eine TNR von 70.97 % und eine Laufzeit um die 140 ms, so dass das analysieren eines großen Bildes der Größenordnung 1000x1000x1000 nur einige Sekunden dauert. Die Accuracy betrug 81.67 % und die Precision 75.00 %.
Eine qualitative Betrachtung der Risse zeigt, dass am besten Risse erkennt werden, die überwiegend mittig verlaufen, breit sind und über wenig Neigung verfügen. Risse, die zu filigran sind, am Rande des untersuchten Bildausschnitts liegen oder sehr stark oszillieren, werden schlechter erkannt. Die Bilder, die fälschlich als Riss klassifiziert wurden, weisen überwiegend Poren auf oder verfügen über einen anderen Helligkeitskontrast, obwohl es auch genügend Poren gibt, die vom Netz als solche erkannt wurden.
In Figure 3 ist ein großes Bild einer Betonprobe zu sehen, welches in 100x100x100 Teilbereiche zerlegt wurde. Diese Ausschnitte haben wir mit unserem Netz klassifiziert. Vor allem der linke und der rechte Zweig wurden gut erkannt. Der obere Zweig, welcher in den vorherigen und nachfolgenden Querschnitten stark oszilliert und filigraner ist, wurde schlechter erkannt. Auf Teilen des Bildes, die so nicht im Trainingsdatensatz repräsentiert wurden, liefert das Netz keine guten Vorhersagen, darunter auch der Rand der Probe und der sehr regelmäßige runde Riss in der Mitte. Bei einigen Poren ist sich das Netz weniger sicher, dass kein Riss vorliegt, klassifiziert diese jedoch trotzdem richtig.
Zusammenfassend kann man sagen, dass unsere Ergebnisse soweit zufriedenstellend sind. Wir erreichen einen hohen Recall und eine gute TNR, das Netz ist sehr performant und selbst sehr große Bilder werden in Sekunden analysiert. Das entwickelte Netz ist in der Lage Risse zu erkennen, die nicht zu fein sind und nicht zu stark schwanken. Insgesamt können mit unserem Netz so Kosten und Zeit gespart werden, die bei manueller Inspektion anfallen würden. Vor einem Praxiseinsatz wäre es jedoch wünschenswert, das Netz noch robuster zu machen. Besonders Risse, die so nicht in den Trainingsdaten vorkommen, bereiten unserem Netz noch Probleme. Einige Lösungsansätze wären hierbei zum Beispiel die Verwendung besserer Daten oder das Verwenden eines Ensembles von verschiedenen Netzen.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 18.01.2022 erfolgreich abgeschlossen.
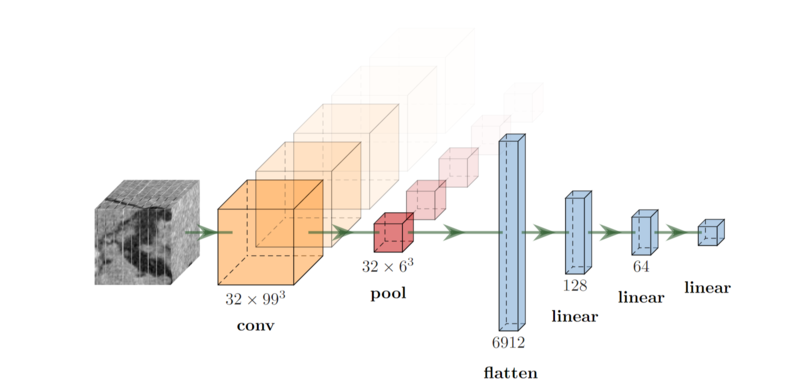
Figure 1: Das verwendete neuronale Netz mit 32 Convolutional Channels.

Figure 2: Bilder des Testdatensatzes.
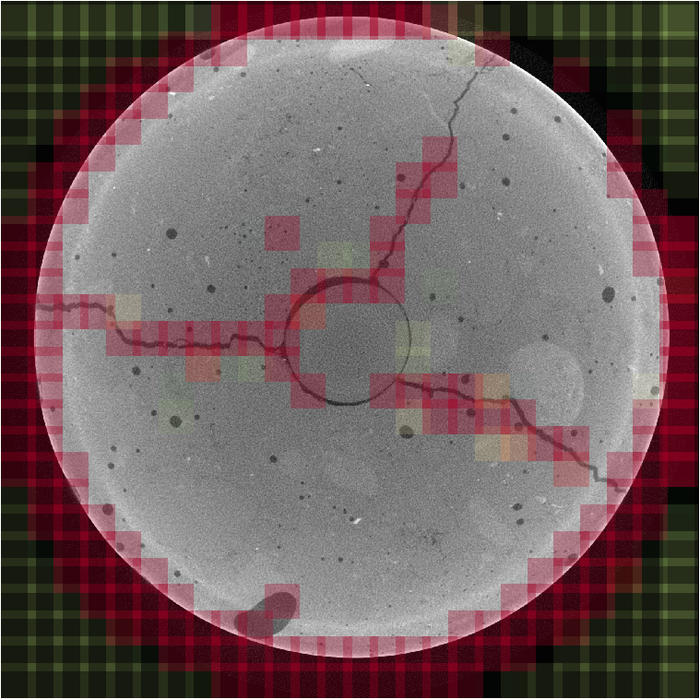
Figure 3: Klassifikation einer großen Betonprobe. Teilbereiche sind entsprechend der Risswahrscheinlichkeit eingefärbt. Rot bedeutet, dass eindeutig ein Riss erkannt wurde, Gelb steht für unsichere Bereiche und bei Grün wird kein Riss erkannt.
#3 Deep Learning für die Charakterisierung von Hauttumoren
Nikolas Dreverhoff & Rudolf Herdt, Universität Bremen
Kooperation: Universität Bremen, MVZ Dermatopathologie Duisburg Essen GmbH
In image classification it has been well established that adversarial examples cause deep neural networks to fail. In this work we generated adversarial examples for semantic segmentation of images, applied on tumor segmentation in digital pathology. Our observation is that adversarial examples also cause deep neural networks for semantic segmentation to fail. We have evaluated for three different U-net architectures how they respond to adversarial examples generated via different methods and have seen that adversarial examples do not transfer well between them. That the network is fooled by changes to its input that are not visible to humans, brings up the question what the network has learned to look for. Therefore, we have visualized features the network is looking for at a given point inside its architecture (at a given layer, channel, or neuron). That goes from edges over patterns to structures, the deeper one goes into the network. Further we applied one method to defend against adversarial examples (Non-Local Means denoising) which improved the prediction of the network compared to the prediction for the adversarial example substantially or nearly not at all.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 10.01.2022 erfolgreich abgeschlossen.
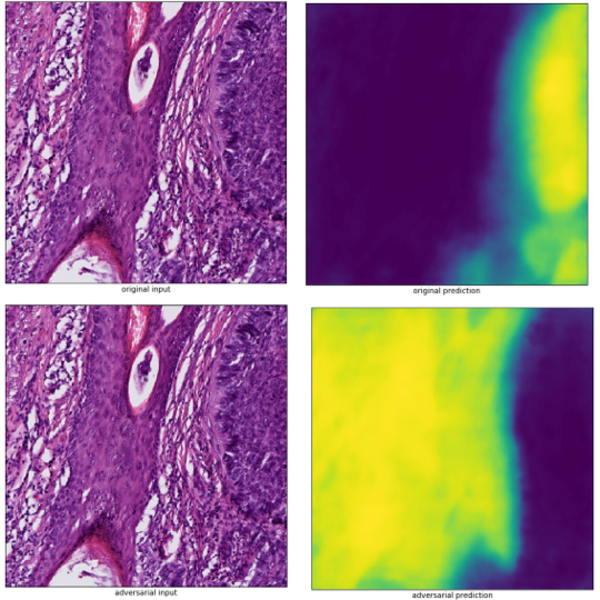
Figure 1: Strong changes between the predictions, while there are no visible changes between the input images. Upper left: original input, upper right: original prediction, lower left: adversarial example, lower right: adversarial prediction.
#5 TPM-basierte dynamische Bildrekonstruktion in der Magnetresonanztomographie
Jacqueline Benzinger & Jennifer Kling, Universität Stuttgart
Kooperation: Universität Stuttgart, Universitätsklinikum Würzburg Experimentelle Radiologie, Universitätsklinikum Würzburg Institut für Diagnostische und Interventionelle Radiologie
Bei Bildrekonstruktionsverfahren wird häufig die vereinfachende Annahme getroffen, dass sich das zu untersuchende Objekt nicht bewegt. Dies ist in der Praxis aber selten der Fall. Aufgrund von beispielsweise organischen Bewegungen kommt es häufig zum Auftreten von Bewegungsartefakten im Rekonstruktionsergebnis. Ein Ziel dieser Untersuchung war es mittels der Entwicklung von Algorithmen die Dynamik des zu untersuchenden Objekts bei der Magnetresonanztomographie (MRT) zu kompensieren. Hierzu wurde die Information der Bewegung über das Tissue Phase Mapping (TPM) mit einbezogen. Die TPM-Daten liefern Geschwindigkeitsvektoren, die die Bewegung im Raum beschreiben. Die Untersuchung zeigte, dass mittels der Verwendung der Vektoren die Bewegungsartefakte reduziert werden konnten. Bei Verwendung des NETT-Verfahrens als Post-Processing-Schritt konnten für unsere Wahl der Parameter die Undersampling-Artefakte nur geringfügig verringert werden. Allerdings konnten wir durch die Verwendung der TPM-Daten im Subgradienten-Schritt der Minimierung des NETT-Funktionals die Bewegungsartefakte weiter verringern. Die Verwendung von datengetriebenen Verfahren zusammen mit den TPM-Daten in der MRT ist für weitere Untersuchungen vielversprechend.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 16.12.2021 erfolgreich abgeschlossen.
#6 Materialprüfung mittels Hochdurchsatz-Nano-Computertomographie
Tom Lütjen & Fabian Schönfeld, Universität Bremen
Kooperation: Universität Bremen, Universität des Saarlands, Fraunhofer IzfP Saarbrücken
Im Rahmen dieses Projektes wurde eine Toolbox entworfen, die es ermöglicht Nano-CT-Datensätze zu erstellen und verschiedene neuronale Netze auf diesen zu trainieren und auszuwerten. Ziel dabei war es, Fehler in der Bildrekonstruktion bei der Nano-Computertomographie aufgrund von korrupten Messdaten, welche durch Abweichungen der Messgeometrie entstehen, mithilfe dieser neuronalen Netze zu minimieren. Die Toolbox bietet die Möglichkeit eine Liste von 3D-Phantomen zu Erzeugen, welche dann mit den klassischen Rekonstruktionsmethoden „gefilterte Rückprojektion“ und „Kaczmarz-Methode“ rekonstruiert werden können. Bei diesen Rekonstruktionen können Abweichungen von der idealen Messgeometrie simuliert werden, welche die Rekonstruktion wesentlich verschlechtern. Mit einer Liste von Phantomen und den dazugehörigen fehlerhaften Rekonstruktionen können Trainings-, Validierungs- und Testdatensätze für die neuronalen Netze erstellt werden. Es wurde ein Skript für das Training eines U-Nets mit den erzeugten Datensätzen implementiert. Des Weiteren bietet die Toolbox die Möglichkeit, die trainierten neuronalen Netze an Testdatensätzen auszuwerten.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 19.01.2022 erfolgreich abgeschlossen.
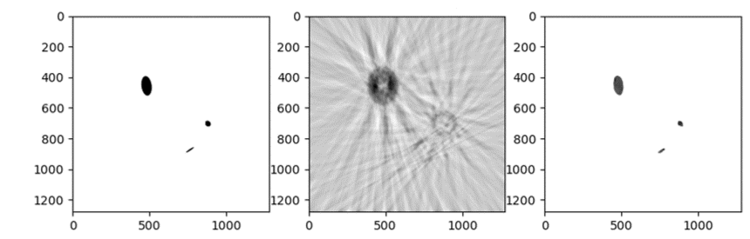
Phantomscheibe (links) mit dazugehörigen Rekonstruktionen mittels der Kaczmarz-Methode (Mitte) und eines trainierten U-Nets (rechts) unter einer Verschiebung des Detektors.
#8 Deep Learning für Predictive Maintenance von Schienenfahrzeugen
David Prenninger, FH St. Pölten
Kooperation: Universität Bremen, DB Analytics, Deutsche Bahn AG
Der Schienenverkehr ist infrastrukturell hoch vernetzt und schon kleine Verspätungen können zu Ketteneffekten führen, welche große Auswirkungen auf die Pünktlichkeit des Gesamtsystems haben. Predictive Maintenance verspricht eine frühzeitige Vorhersage von Bauteilausfällen und damit eine bessere Planbarkeit von Instandhaltungsmaßnahmen. Dies führt im Betriebsablauf zu einer Reduktion von unerwarteten Ausfällen und damit einer Verbesserung der Pünktlichkeit. Zu diesem Zweck aggregierte Daten weisen jedoch meist - trotz langer in den Daten abgebildeten Zeiträumen - eine niedrige Zahl an Ausfällen auf. Eine Klassifizierung dieser ist daher als "small data problem" zu betrachten. Aufgezeichnete Ausfälle können dabei unterschiedlicher Ausprägung und Ursache sein, was eine Generalisierung der Ausfallklasse weiter erschwert. Ziel der Challenge war es, mit neuen Ansätzen aus dem Unsupervised Learning Türstörungen auf Basis von Diagnosedaten vorherzusagen. Zu Beginn des Projekts wurde dazu eine stratifizierte Aufteilung des Datensatzes in Test-, Training- und Validationdatensatz vorgenommen, um möglichst gleiche Anteile der Ausfälle in allen drei Datensätzen zu erzielen. Um sogenanntes Information Leakage zwischen Datensätzen zu vermeiden, wurden alle gesammelte Werte zu einer Tür einem einzigen Datensatz (also Test-, Trainings- oder Validierungsdatensatz) zugeordnet.
Als besonders spannende Konzepte wurde im Weiteren der Uniform Manifold Approximation & Projection Algorithmus (kurz UMAP), und ein Auto-Encoder Modell optimiert und mit Supervised Learning verglichen. Es zeigte sich dabei, dass die Vorhersagen generell eine niedrigere Precision erzielten, jedoch einzelne Ereignisse, welche durch ein Supervised Learning Modell nicht erkannt wurden, als Anomalien klassifiziert werden konnten. Um das Beste aus beiden Welten nutzbar zu machen, könnte es sich daher anbieten eine Verbindung von Supervised und Unsupervised Learning Modellen in einem Ensemble Modell an.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 07.02.2022 erfolgreich abgeschlossen.
#10 Deep Learning für die Detektion von interiktalen epileptischen Spikes
Fabienne Anselstetter & Patricia Schell, Hochschule Ansbach
Kooperation: Hochschule Ansbach, BESA GmbH
Die Detektion von interiktalen epileptischen Spikes (IES) ist ein wichtiger Bestandteil der Epilepsiediagnostik. Um ein KI-Modell zu identifizieren, welches für die automatische IES-Detektion hinreichende Klassifizierungsergebnisse aufzeigt, wurden verschiedene Modelle des Machine Learnings (ML) und des Deep Learnings (DL) mit EEG-Daten trainiert. Hierbei wurden neben etablierten ML-Methoden, wie K-Nächste-Nachbarn, Entscheidungsbäume, Random Forests, Gaussian Naive Bayes, Support Vector Machines und Passive Aggressive Algorithmen auch drei Convolutional Neural Networks (CNN) aus dem Bereich des DLs mit unterschiedlicher Tiefe verglichen. Mit einer Test-Genauigkeit von 94,15% stellt die Support Vector Machine das für die Daten am besten geeignete ML-Modell dar, wohingegen mit dem tiefsten CNN sowohl eine höhere Test-Genauigkeit von 96,50% als auch eine Falsch-Positiv-Rate von 0,63% erreicht werden konnte. Die Ergebnisse des Projekts bestätigen, dass datenbasierte DL- Ansätze parametrischen ML-Ansätzen überlegen sind. Der effektivste DL-Ansatz kann durch zukünftige Forschungsschritte weiter verbessert werden.
Abschluss
Das Projekt wurde mit der Präsentation der Projektergebnisse am 09.11.2021 erfolgreich abgeschlossen.
Kontakt
Prof. Dr. Dr. h.c. Peter Maaß
Zentrum für Technomathematik
Universität Bremen
Bibliothekstraße 5
28359 Bremen
pmaass@uni-bremen.de

